Mitigating Attention Collapse via Mean-Deviation Constrained Optimization
Techrxiv, 2025 [🌐 Preprint Online] [📃 Preprint Full-Text]
- Abstract
- Additional Comments
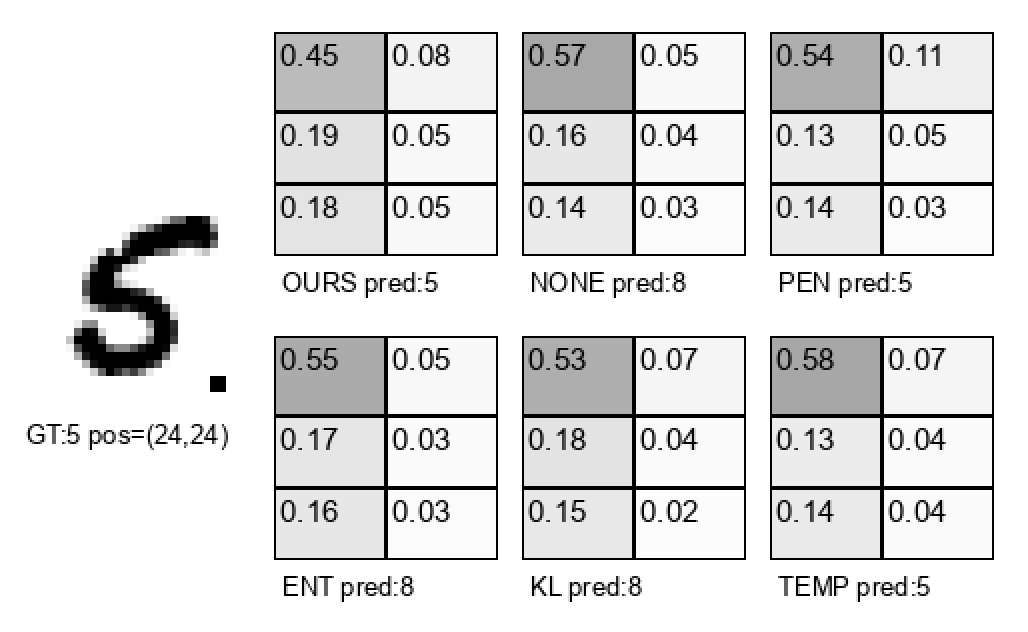
Attention mechanisms are widely used in deep learning to compute contextual representations, but they are prone to collapse when attention weights concentrate excessively on a few tokens, potentially degrading model performance. We propose an Mean-Deviation Constrained Attention (MDCA), an optimization-based attention mechanism that constrains the mean-deviation of attention weights to mitigate attention collapse. The constraint is formulated as an inequality condition and is efficiently handled using the Augmented Lagrangian Method (ALM), enabling explicit control over attention concentration. Unlike heuristic approaches such as dropout or temperature scaling, our method introduces a principled regularization framework grounded in constrained optimization. We evaluate the proposed method on two tasks: (i) selective attention for handwriting classification using the Badge-MNIST dataset, in comparison with standard baselines including vanilla attention, entropy regularization, and temperature scaling; and (ii) imitation learning on the nuPlan dataset, compared with a representative state-of-the-art planner. On Badge-MNIST, our method improves attention selectivity and accuracy across seeds. On nuPlan, it yields safety driving in reactive closed loop and openloop evaluation while maintaining modest.