State-Dependent Lagrange Multipliers for State-Wise Safety in Constrained Reinforcement Learning
TechRxiv, 2025 [🌐 Preprint Online] [📃 Preprint Full-Text]
- Abstract
- Additional Comments
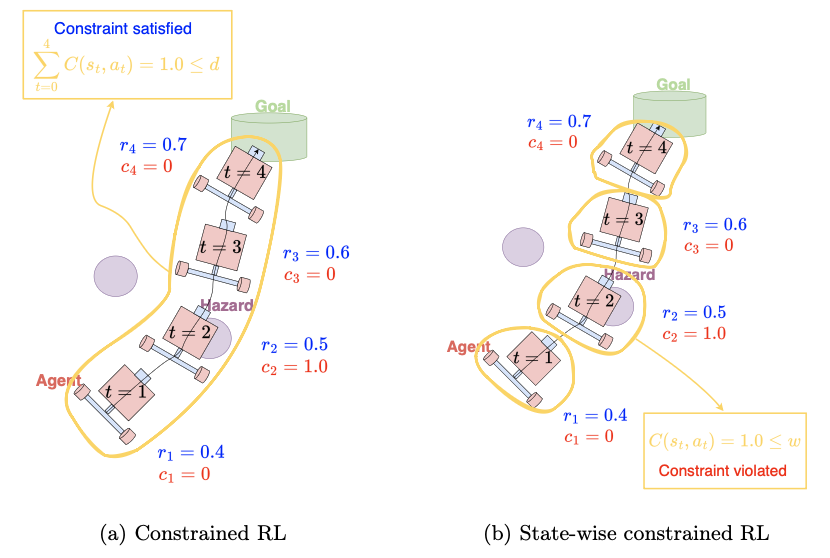
Despite the remarkable success of deep reinforcement learning (RL) across various domains, its deployment in the real world remains limited due to safety concerns. To address this challenge, constrained RL has been extensively studied as an approach for learning safe policies while maintaining performance. However, since constrained RL enforces constraints in the form of cumulative costs, it cannot guarantee state-wise safety. In this paper, we extend the Lagrangian based approach, a representative method in constrained RL, by introducing state-dependent Lagrange multipliers so that the policy is trained to account for state-wise safety. ㄴOur results show that the proposed method enables more fine-grained specification of the constraints and allows the policy to satisfy them more effectively by employing state-dependent Lagrange multipliers instead of a single scalar multiplier.