State-wise Safety in Autonomous Driving via Lagrangian-based Constrained Reinforcement Learning
라그랑지안 기반 제약 강화 학습을 통한 자율주행 시스템의 상태별 안정성 보장
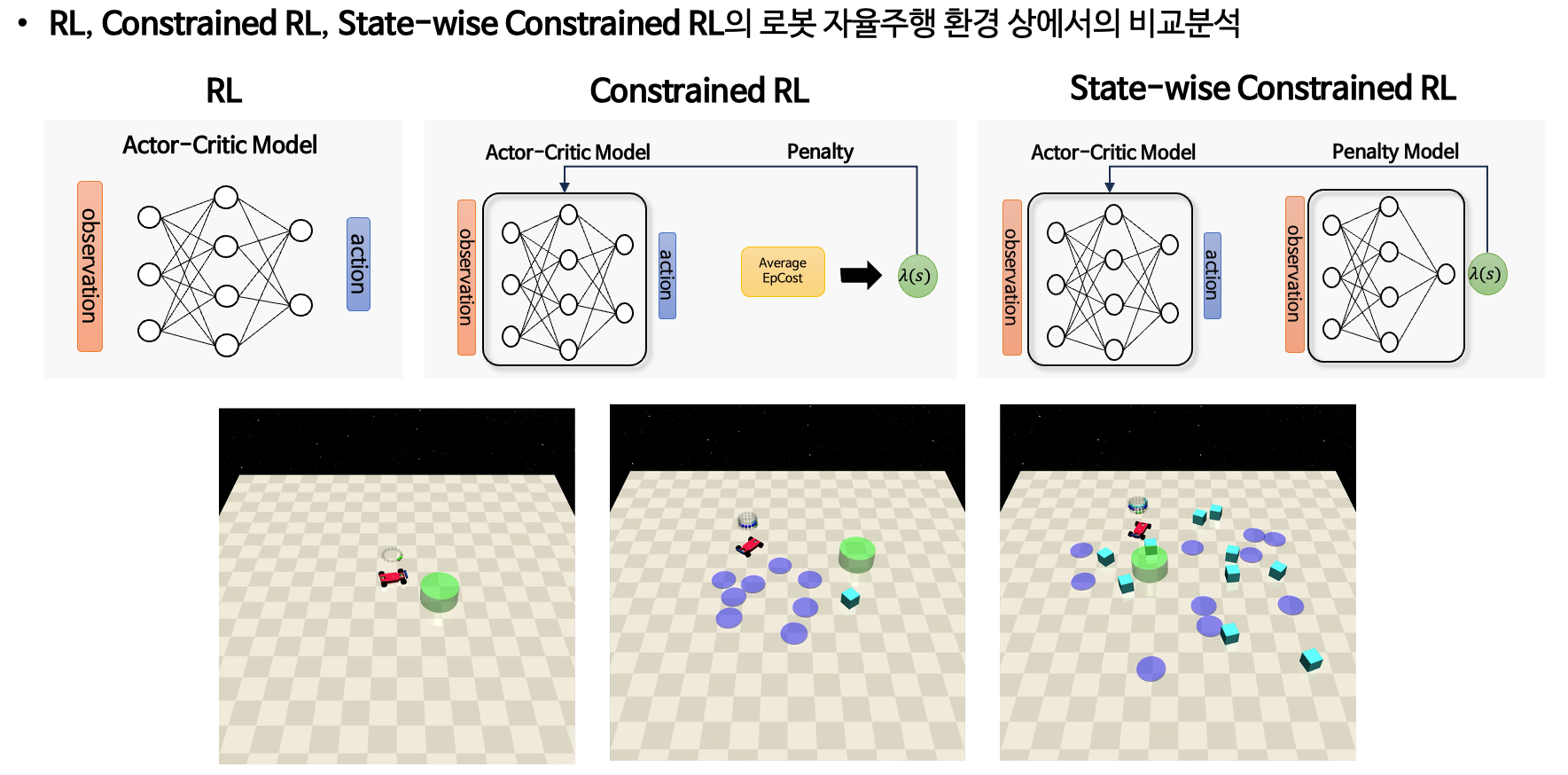
- Abstract
- Additional Comments
자율주행 시스템의 실제 적용을 위해서는 높은 안정성과 적응성이 요구된다. 이를 위해 시뮬레이션을 통해 스스로 주행 전략을 학습하는 심층 강화 학습(Deep Reinforcement Learning, DRL)이 주목받고 있다. 그러나 심층 강화 학습은 보상 설계, 학습 분포 외의 상황에 대한 일반화 실패 등으로 인해 실제 적용 시 안전 문제가 발생할 수 있다. 이를 해결하기 위해 정책 학습 시 안정성과 성능 간의 균형을 도모하는 제약 강화 학습(Constrained Reinforcement Learning)이 제안되었다. 제약 강화 학습은 일반적으로 기댓값 기반 누적 비용 형태로 제약을 정의하는 제약 마르코프 결정(Constrained Markov Decision Process, CMDP)에 기반하는데 자율주행에서는 충돌 회피와 같이 즉각적인 반응이 요구되는 제약들이 존재하기 때문에, CMDP에서 정의한 누적 제약을 만족하도록 학습하더라도 이러한 즉각적인 제약을 위반하는 위험한 상황이 발생할 수 있다. 따라서 본 논문에서는 라그랑지안 기반 정책 최적화 방법을 통해, 상태별로 라그랑주 승수(Lagrangian multiplier)를 추정하여 제약 조건을 정밀하게 반영함으로써 상태별 안정성을 보장하고자 한다. 제안한 방법은 OpenAI의 시뮬레이션 환경인 SafetyGym에서 차량이 지정된 목표 지점까지 이동하는 태스크를 통해 검증하였다.